Overview
This page will consist of two sections: a brief section on some lessons learned from this internship and a longer report describing in detail the agent architecture we used. For a detailed report on how our Django backend works, please see this.
Feel free to reach out on LinkedIn or email me at jc3579@cornell.edu if you have questions.
Lessons Learned, Part 2
In my first lessons learned post, I discussed how we used RAG in a specific way to address a specific use case: customizing advice based on referring doctor. This allowed us to have a different corpus of experts on whom to RAG based on which doctor was referring. However, this led us to one big issue: some more prolific experts, with more content on the internet, were overpowering the retrieval, even in areas not under their expertise. For example, if I asked a question about sleep, due to the sheer amount of his content, Mark Hyman’s content would always come out on top over Matthew Walker, the actual sleep expert.
In hindsight, the solution we arrived at sounds obvious, but it actually wasn’t the first thing we thought of. We first tried to exclude content that seemed extraneous or low-quality, but that didn’t guarantee that prolific experts would overpower more specialized ones.
What we ended up doing was use a mapping from specialty to expert as well as a categorization of the question in order to filter to a specific source or set of sources. For example, if I asked “how much sleep should I be getting?”, the question would be categorized by an LLM as sleep, then the RAG would only retrieve chunks from the relevant sleep experts.
Agent Architecture Report
System Overview
Jarvis In Your Pocket is an AI health companion you can chat with in plain English. You ask a question, Jarvis thinks through what tools it needs, and it replies while showing progress in real time. Under the hood, it keeps track of your conversation, saves important information to a database, and uses trustworthy sources when it gives health guidance.
In everyday use, Jarvis can log what you eat, help you choose meals at restaurants, answer health questions using sources your doctor would recognize, and update your profile without you filling out forms. Over time, the goal is to give Jarvis a deeper, privacy‑respecting memory so it can personalize help even more.
Code Locations:
- Main chat endpoint:
django_backend/health_api/views.pylines 1158-1200 - Database models:
django_backend/health_api/models.pylines 1-150 - Frontend chat interface:
django_backend/static/js/main.jslines 2330-2500
Core Architecture
Code Locations:
- Main agent class:
django_backend/health_api/unified_agent.py - Chat endpoint:
django_backend/health_api/views.pylines 1158-1200
Unified agent framework
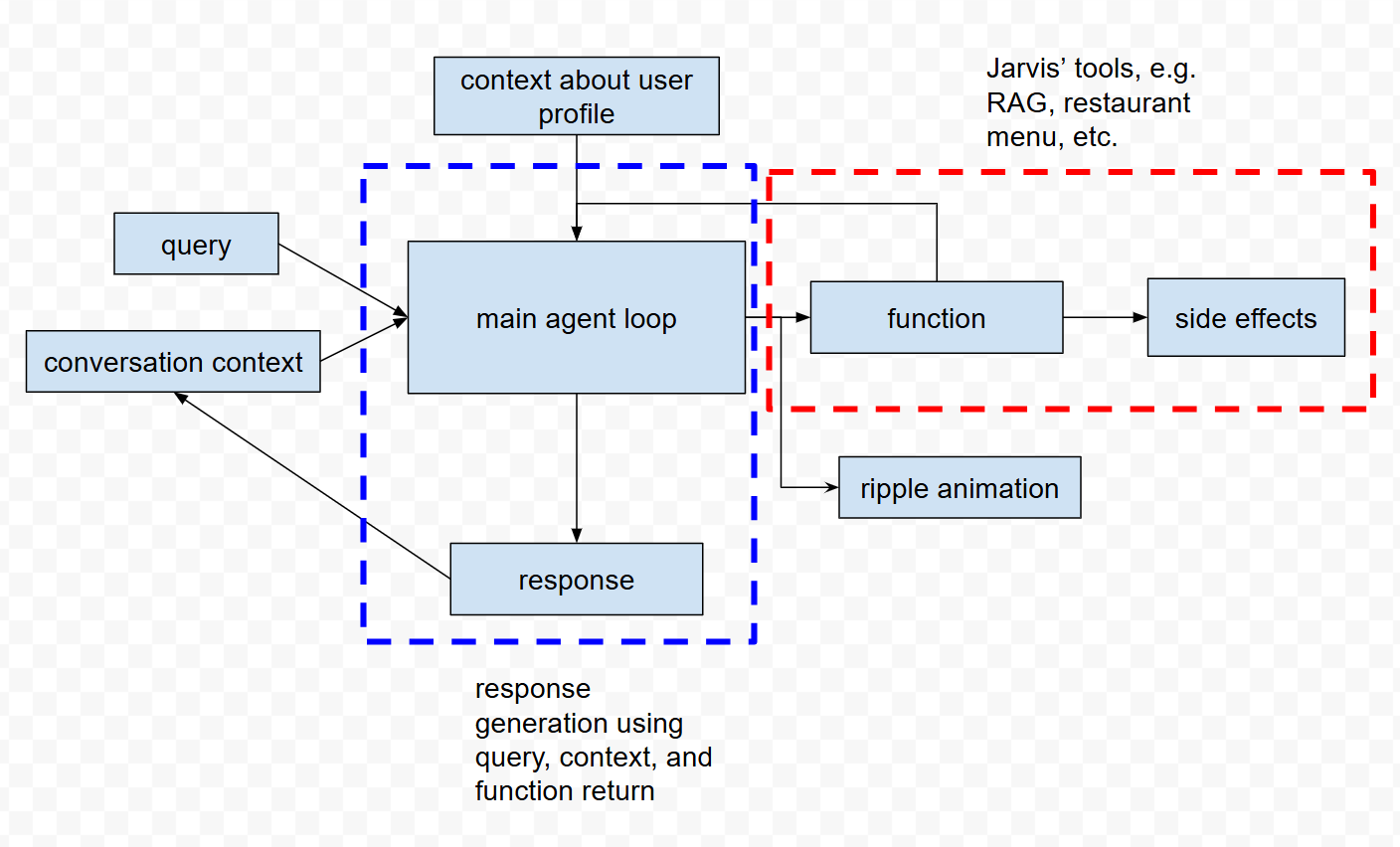
At the center is one “big loop” that receives your message, decides what to do, and produces an answer. We call this the unified agent loop, implemented in a UnifiedJarvisAgent class. Rather than hard‑coding every scenario, the agent chooses from small, focused functions (for example, “log food” or “search health info”) and composes them as needed.
When Jarvis replies, it doesn’t wait until everything is finished. It streams its response in small chunks and triggers simple animations like “searching” before the response starts streaming so you can see progress. For conversation context, we use LangChain’s memory helpers to keep just the relevant recent messages, which helps Jarvis stay on topic without getting confused by very long histories.
Key components in plain terms
- OpenAI models (GPT‑4o for web/tool use and GPT-4.1 for everything else) power the natural language understanding and the “function calling” that lets the model politely ask our code to do specific tasks.
- A PostgreSQL database, accessed through Django’s ORM, stores durable information like food logs and profile updates so the data survives app restarts and is easy to query later.
- A retrieval system known as RAG (retrieval‑augmented generation) uses a vector database (Pinecone) to look up relevant expert health sources before the model drafts an answer. In short: we search trusted documents first, queried both by health category and which doctor referred, then let the model write with those facts in view.
- A web search capability, called through OpenAI’s Responses API, lets Jarvis check the current web for things like live restaurant menus when static sources aren’t enough.
Function Calling System
Code Locations:
- Function definitions:
django_backend/health_api/unified_agent.pylines 86-250 - Food logging:
django_backend/health_api/unified_agent.pylines 423-523 - Health info search:
django_backend/health_api/unified_agent.pylines 324-422 - Restaurant search:
django_backend/health_api/unified_agent.pylines 524-623
The functions Jarvis can call (red box in diagram)
Jarvis picks from a small set of clear tools:
- Food logging (
log_food_intake): Given a sentence like “I ate a chicken burrito,” Jarvis identifies the food, estimates nutrition (calories, protein, etc.), and saves an entry for you. - Health information (
search_health_info): For questions like “Is omega‑3 helpful?”, Jarvis searches our expert sources first (via RAG) and then explains the finding in simple language. - Restaurant menu analysis (
search_restaurant_menu): When you name a restaurant and your goals, Jarvis looks up the current menu online and suggests items that meet your targets. - Profile updates (
update_user_profile): If you say “Change my weight goal,” Jarvis updates the profile fields in the database so future advice stays aligned.
Of these functions, food logging and profile updates have side effects, namely updating the database accordingly. Food logging, as well as health information and restaurant menu searching, have return values which the main agent loop can use to appropriately formulate a response.
How a single query turns into an answer (important)
When you send a message, the model first decides which function(s) are needed. We immediately show a small animation (like “searching the web”, this is the called “ripple” animation in the diagram) so you know work is happening. The code then runs the chosen function—sometimes alongside a database query/side effect—and collects the results. With that context in hand, the model drafts a conversational answer (red box in diagram). Finally, we stream that answer back to the app so you can read it as it appears, rather than waiting for a long pause and a single wall of text.
Advanced Features
Code Locations:
- Memory management:
django_backend/health_api/unified_agent.pylines 60-85 - Context storage:
django_backend/health_api/models.pylines 120-150
Memory and context management
Jarvis remembers what happened in the current chat session so it can follow along naturally. We intentionally keep that memory “window” small so past details don’t overwhelm the current topic. We use LangChain’s ConversationBufferWindowMemory for this. On the output side, we apply a light formatting pass that fixes occasional spacing issues and keeps the tone friendly and conversational—more like a helpful health coach than a reference manual.
Performance Optimizations
Making the loop fast without losing quality
Because there is a single agent loop, we can optimize once and benefit everywhere. Web lookups go through a streamlined path that pairs GPT‑4.1 with the Responses API’s GPT-4o web tool, and the UI animations are triggered directly from function choices so feedback feels instant.
We also added “fast paths” for simple messages. If you say something like “thanks” or ask a very small follow‑up, Jarvis recognizes the pattern and responds quickly without spinning up unnecessary tools. This makes common interactions feel snappy. The trade‑off is that some complex answers may take a little longer, but overall the experience is both responsive and thorough.
Restaurant Query Processing Example
Real System Flow: “I am planning to have dinner at Teleferic Barcelona in Los Gatos tonight - what should I eat to stay under 1000 calories, get 60 grams of protein and 15 gms fiber”
Here is what actually happens with a real example. Suppose you say: “I’m planning dinner at Teleferic Barcelona in Los Gatos—keep me under 1,000 calories with 60g protein and 15g fiber. What should I order?”
Step 1: Understand the request and pick a tool
The agent parses your message and recognizes it as a restaurant request. Using OpenAI’s “function calling” ability, it selects our search_restaurant_menu tool to find current menu items that match your goals. In code, this selection happens in UnifiedJarvisAgent.process_message_stream() and the function itself is defined in _define_functions().
Step 2: Show progress right away
Before the network request even finishes, the system streams a small token like “SEARCHING_WEB_ANIMATION” to the UI. That way, you immediately see that Jarvis is working, instead of staring at a blank screen.
Step 3: Run the restaurant search
The agent enriches your query with your calorie, protein, and fiber targets, then calls a helper (get_restaurant_web_search) that performs a web search for current menu details.
Step 4: Use the web responsibly
The web search helper builds a clear, structured prompt so the model knows exactly what to retrieve and how to format the results:
search_prompt = f'''
Find current menu items and nutrition info for {restaurant_name} that match: {query}
Focus on:
- 3-5 specific menu items with calorie/protein info
- Healthy options that meet dietary goals
- Include source links for each recommendation
Format: "Item name ([source](url)) - calories, protein"
Keep response concise.
'''
It then calls OpenAI’s Responses API with the web search tool enabled, which lets the model use a browser‑like capability to gather live information:
response = client.responses.create(
model="gpt-4o",
input=search_prompt,
tools=[{"type": "web_search"}]
)
Step 5: Draft and stream the answer
Once results come back, the agent weaves them into a short, friendly recommendation that cites sources. It streams the answer piece by piece so you can start reading without delay.
In conclusion, for this particular prompt, the data flow through the diagram is as follows: query => main agent loop => restaurant menu function => main agent loop => response.
Code Locations:
- Query processing:
django_backend/health_api/unified_agent.pylines 284-404 - Restaurant search:
django_backend/health_api/rag_service.pylines 458-500 - Function definitions:
django_backend/health_api/unified_agent.pylines 86-110 - Animation system:
django_backend/health_api/unified_agent.pylines 714-728
Comprehensive Test Suite
Code Locations:
- Main test file:
django_backend/test_unified_agent_functions.py - Test suite interface:
django_backend/templates/admin/test_suite.html
Overview
We test Jarvis end‑to‑end using the same streaming pipeline the app uses in production. That means our tests are realistic: the agent calls the same functions, touches the same database, and produces the same kind of streaming messages users see. We don’t lock tests to a single “perfect” sentence—because language can vary—but we do check that the right functions run, data is saved correctly, and the final response reads sensibly. Specifically, we check response length, whether it RAGs and if so whether the category was correct, whether it logged food, and whether the ripple animation text was correct (which indicates whether the correct function was used).
The reason this is useful is because we have a set of behaviors we want Jarvis to adhere to, and at any time, we can run all of the tests to make sure that Jarvis does behave correctly. The test suite can also help with test-driven development. The test suite page is accessible at /system/admin/test-suite.
Test Architecture
Our main test file is django_backend/test_unified_agent_functions.py. Tests instantiate the real agent with streaming turned on. They operate against the same PostgreSQL database schema, but with isolated test users and session flags so no test runs pollute real chat history. Authentication uses dedicated accounts that mirror production, keeping the flow realistic.
Test Categories
We cover both one‑shot prompts and longer conversations.
1) Single‑prompt function checks
These tests send simple messages to validate each tool end to end. Examples include:
- Food logging: “I ate 2 eggs and bacon for breakfast.”
- Weight tracking: “I weigh 155 pounds today.”
- Health information: “Tell me about the benefits of omega‑3.”
- Profile updates: “Update my weight goal to gain muscle.”
2) Multi‑turn conversations
These tests exercise memory and context. We simulate:
- Progressive food logging across a day, making sure totals add up.
- Health consultation flows with follow‑up questions and clarifications.
- Recipe recommendation chains that move from preferences to concrete dishes.
- Restaurant analysis that starts from location, narrows by cuisine, and ends with specific items.
Test Execution Process
Step 1: Start an isolated session
Each test creates a unique session tied to a designated test user so data stays separate from real users:
# Each test creates isolated session
test_user = User.objects.get(username='test_user_agent_functions')
session_id = f"test_session_{int(time.time())}"
Step 2: Talk to the real streaming endpoint
Rather than calling internal functions directly, tests hit the same streaming HTTP endpoint the app uses. That keeps behavior honest:
response = requests.post('http://localhost:5000/api/chat/stream/', {
'message': test_message,
'user_id': test_user.id,
'session_id': session_id,
'test_mode': True # Flags as test chat
})
Step 3: Check that the right things happened
We verify that the expected function ran, that any database side effects (like new food entries) exist, and that the response reads clearly. Error paths are exercised too, to confirm the system fails gracefully and recovers.
Test Data Validation
Database verification
Where a test implies a write—like logging food—we assert the database really changed:
# Example: Food logging test verification
food_entries = DailyFoodLog.objects.filter(user=test_user, date=today)
assert len(food_entries) > 0
assert any('eggs' in entry.food_name.lower() for entry in food_entries)
Multi-Prompt Test Examples
Health consultation flow
- Initial context: “I have diabetes and high blood pressure.”
- Follow‑up: “What breakfast foods should I avoid?”
- Clarification: “Is oatmeal okay for my conditions?”
- Expectation: The agent carries context across turns and tailors advice.
Restaurant analysis chain
- Location: “I’m near downtown San Francisco.”
- Preference: “I want healthy Mexican food.”
- Goal: “Under 600 calories with high protein.”
- Expectation: The agent respects location and cuisine while meeting nutrition targets.
Test Isolation and Cleanup
Session management
All test chats set test_mode=True, which hides them from normal history views and flags them for cleanup. Temporary session IDs prevent collisions.
Data isolation
We use dedicated test users and tagging so it’s easy to find and remove any artifacts. This separation protects production data and keeps tests deterministic.
Performance Testing
We measure not just whether Jarvis answers, but how quickly and reliably it does so. Streaming tests track how fast chunks arrive. Database tests time common operations to catch slow queries. Memory tests check that the conversation window stays bounded. Finally, we simulate multiple users at once to make sure the system remains stable under load.
Test Reporting
Our reports summarize pass rates, response quality checks, and correctness of side effects (like accurate database writes). We include timing data and resource usage to spot regressions early, and we keep detailed error logs to speed up debugging when something breaks.
Real-World Simulation
We write tests in the same everyday language people use and deliberately switch topics mid‑conversation to verify Jarvis keeps up. We feed it unclear or contradictory inputs to test recovery, and we include edge cases that are uncommon but realistic. The result is a test suite that mirrors real usage, not just happy‑path demos.